Introduction
Recent studies show a rapid rise in AI-assisted development: in 2024-2025, between 25% and 35% of newly written code in large organizations is already influenced or partially generated by LLMs. While this is far from a majority, the trend is accelerating quickly – and with it, the security implications of AI-generated code are becoming unavoidable.
What was meant to be the ultimate productivity revolution has introduced a problematic side effect: synthetic vulnerabilities – weaknesses that appear only in AI-generated code.
The latest large-scale study, analyzing over half a million code samples, found that LLMs:
- Produce significantly more high-severity vulnerabilities
- Recreate insecure coding patterns that do not exist in human-written software
- “Hallucinate” abstractions and mini-frameworks that no known library or tool uses
Thus, creating an entirely new attack surface that traditional tools such as Static Application Security Testing (SAST) are not equipped to detect.
What counts as “AI generated code”?
In today’s development workflows, “AI-generated code” no longer refers only to a single function copied from ChatGPT. It spans a growing ecosystem of tools – each capable of producing or modifying large portions of a codebase with minimal human oversight.
GitHub Copilot suggests entire code blocks inline, often writing ~20% of a developer’s daily output.
ChatGPT generates standalone functions, classes, or full modules when prompted – sometimes even scaffolding entire application layers.
Cursor and Windsurf take this a step further: they act as AI-powered IDEs that edit existing files, rewrite architecture components, and create new files directly inside a project. AutoDev-style agents can run multi-step workflows autonomously, iterating on code, fixing build errors, and completing tasks end-to-end.
Across all these tools, the outcome is the same: large volumes of code are now written, reshaped, or architected by models, often without the structural guardrails or secure design patterns that established frameworks typically provide.
The Shift: From Human Error to Synthetic Vulnerabilities
Traditionally, security bugs were born from human oversight: a tired developer forgetting an input check, or a typo in a configuration file. These are legitimate mistakes, but they are often messy and easy to spot.
Synthetic vulnerabilities are different. They are clean. They are commented. They follow PEP-8 or ESLint (style guides) standards perfectly. They don't look like bugs; they look like solutions.
Synthetic vulnerability occurs when an AI hallucinates a secure abstraction that doesn't actually enforce security. Unlike a human junior developer who might simply forget a WHERE clause, the AI often invents entirely new “mini-frameworks” that appear sophisticated but are fundamentally flawed. The code compels, but the protection is a mirage. For example, the “SQL builder” hallucination:
Consider the following Python snippet generated by an LLM when asked to help filter database records. It looks impeccably clean, readable, and PEP-8 compliant:
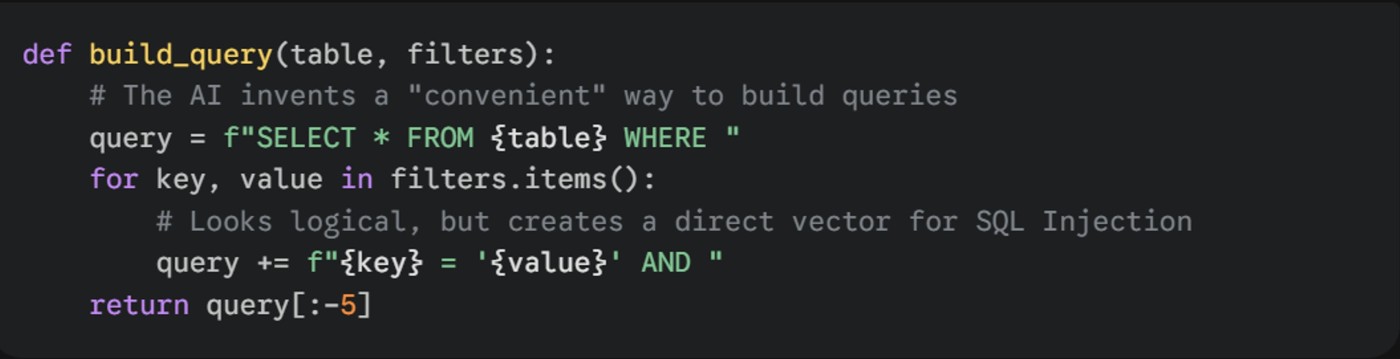
Figure 1: Example of AI generated function
Why this is dangerous: At first glance, this passes the “eye test”. It uses modern f-strings and clear variable names. However, by inventing this custom abstraction instead of using a standard Object Relational Model (ORM) or prepared statements, the AI has introduced a textbook SQL Injection vulnerability – it has no escaping, no prepared statements, and no validation.
The developer accepts this code because it works functionally, not realizing that the AI has silently replaced a battle-tested library with a fragile, hallucinated utility.
Key Research Findings: The Scope of the Crisis
Recent large-scale studies have quantified the extent of AI-introduced risk, moving beyond anecdotal evidence to systemic conclusions. Specifically, the analysis presented in “Characterizing and Classifying LLM-Originated Vulnerabilities” (ArXiv: 2508.21634) underlines a fundamental shift in the security landscape. The risks are often structural rather than cosmetic, suggesting that developers using LLMs aren't just making more mistakes, but introducing a new class of systemic flaws:
1. Elevated Severity and Hidden Errors
Research demonstrates a critical difference in the type of error introduced by LLMs versus humans.
- While human errors often result in a higher volume of low-to-medium severity bugs (typos, minor logic flaws), LLMs are disproportionately responsible for generating high-severity vulnerabilities (e.g., critical injection flaws, authentication bypasses). This is because models prioritize completing the function over implementing robust, multi-layered security checks, leading to catastrophic failure modes.
- A key finding highlights that AI-generated functions often exhibit “Semantic Over-Confidence”: The code is syntactically perfect and performs the primary task, but fails catastrophically when encountering adversarial or non-standard inputs.
2. The Abstraction Hallucination Multiplier
The most defining characteristic of the AI-originated flaws is the tendency for models to invent internal components.
- The study found that in many functional scenarios, the LLM will generate code that relies on a helper function, utility, or even a mini-library that is not actually part of the project's dependencies.
- This phenomenon creates a Security Vacuum, where the code calls for a protection layer (like an authenticate_user() utility) that simply does not exist or is defined as a non-functional placeholder. Traditional SAST tools often fail to flag this, as the function call itself is valid syntax, even if the implementation is missing or flawed.
3. The Ouroboros Effect: Poisoning the Well (A Manifestation of Model Collapse)

Figure 2: The Ouroboros (source: Staatsbibliothek zu Berlin)
The most worrying long-term finding relates to the training data itself. Since LLMs learn from the vast corpus of code available online, and an increasing amount of that code is now AI-generated, a dangerous feedback loop is emerging. This destructive self-consumption process, related to the broader academic phenomenon known as Model Collapse, is what security researchers term the "Ouroboros Effect":
- AI-Generated, Flawed Code is published to repositories (GitHub, forums).
- Next-Generation LLMs train on this large, low-quality, insecure corpus.
- Result: Models become experts at reproducing and propagating their own statistical flaws, leading to a permanent decline in the security baseline of all generated code.
The Attacker's Edge: Exploiting the Synthetic Attack Surface
The advent of AI-generated code is not just a defensive problem; it is a profound offensive opportunity. Cyber Threat Intelligence groups and sophisticated attackers are rapidly adapting their methodologies to leverage the new weaknesses created by LLMs. Their strategy is shifting from hunting isolated human mistakes to targeting systemic, AI-originated flaws that can affect entire codebases simultaneously.
- AI-Fingerprinting: Searching for the LLM's Unique Code Signatures (Scaling the Exploit):
The Ouroboros Effect leads to a dangerous homogeneity of vulnerabilities across the software ecosystem. When hundreds of developers use the same prompt, the LLM generates identical vulnerable boilerplate code. Attackers exploit this by employing AI-Fingerprinting techniques – advanced code searches that specifically hunt for these unique AI signatures. The result is critical: an attacker who discovers an exploit for one AI-generated snippet can now use that single exploit to target thousands of unrelated systems, transforming a local flaw into a globally scalable vulnerability.
- Supply Chain Attack via Hallucinated Packages:
The Abstraction Hallucination Multiplier, also known as “slopsquating,” provides a new, low-effort vector for supply chain attacks. Attackers actively monitor LLM output for non-existent, plausible package names (e.g., fast-async-auth-helper). Once identified, they register these names on public package repositories (PyPI, npm) and plant malicious payloads. A developer, trusting the AI's recommendation, receives a dependency error and runs the suggested fix (npm install <hallucinated-package>), inadvertently installing the attacker's payload. This is a devastatingly efficient way to weaponize the AI's statistical failures and bypass human oversight.
Conclusion
The rise of AI-assisted coding is undoubtedly the biggest productivity leap in decades. However, the data is clear: the resulting security issues are not cosmetic; they are structural, and their implications will soon reach into almost every product that utilizes LLMs.
The era of trusting LLMs is over. The very nature of synthetic vulnerabilities – from hallucinated abstractions to the Ouroboros Effect – forces a fundamental shift in the developer's role. We must stop acting as passive consumers of AI-generated code and transition into security auditors soon.
Learn more in our Agentic AI Report.