Automation is an interesting conversation that I have had with many of our customers lately, especially with cloud migration in play and DevOps processes with continuous development becoming prevalent.
We have seen many service disruptions in large cloud service providers. For example, in 2017, Amazon Web Services (AWS) had its services disrupted on the U.S. East Coast, and Telstra, that offers voice and data services in Australia, had a nationwide outage in Feb 2016. In 2013, NASDAQ data feeds for valuation of electronic trades went down. All of these companies had redundancies. The reason for the disruption was human error. It is obvious that outages have major negative economic impact.
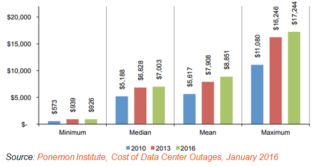
An estimate from Ponemon Institute is around USD $8,900 per minute!
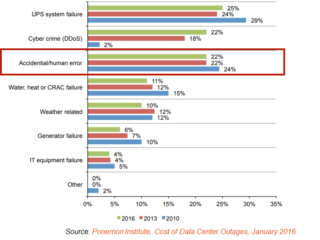
According to the same study by Ponemon Institute, of all the reasons for the data center outage, about 22% was associated with human error. That is significant.
A separate study, by Dimensional Research, tried to associate the error that has the most significant impact – you guessed it – network configuration changes. In fact, 97% of all the outages had a human component. Furthermore, 74% of the time a change can negatively affect a business monetarily.
[You might also like: Operational Visibility for Load Balanced Traffic in SDDC]
The bottom line: Human factors lead to network outages, and in many cases, these outages are frequent AND expensive.
Which brings us to automation. Of course, you should automate to reduce errors and business disruption, but when does it become pressing? The rationale to automate could be related to resource constraints, configuration management, and compliance or monitoring. Of course, there are others, but I am just highlighting the most obvious one.
It may be that you have very few people managing a large set of configurations, or the skillset required for the task is broad, complex or lacking – say spanning networking and security portfolio, or the network operation team does not have the operational knowledge of all the devices under management.
Begin with the end in mind
If the objective is to use gradual change to move toward a near automated operation that can be orchestrated, then define the steps to that goal – as Dr. Stephen Covey says, “Begin with the end in mind.”
The success is made of several incremental steps that build upon each other. For example, identify use cases where configuration change is prone to introducing errors. Then take steps to make them scripted and repeatable – using existing tools, which may be CLI or python scripts. You are now at a point where you are ready to automate.
Now you have to pick tools that will help you simplify the tasks, remove the complexity, and make it consumable to your audience.
Let us say you have a use case where a development engineer has an application ready and needs to test application scalability, business continuity and security using a load balancer, prior to rolling out. The developer may not have the time to wait for a long provisioning timeline nor the expertise and familiarity of the networking and security configurations. The traditional way would be to open a ticket, have an administrator reach out, understand the use case and then create a custom load balancer for the developer to test. Certainly expensive to do, and hinders continuous integration and continuous delivery (CI/CD) processes.
[You might also like: Load Balancers and Elastic Licensing]
The objective here would be enable self-service, in a way that the developer can relate to and work with to test against the load balancer without networking and security intricacies coming in the way. A common way of doing this would be to create a workflow that automates tasks using templates, and if the workflow spans multiple systems then hides the complexity from the developer. Many such integrations for orchestration systems are available from vendors for common tools such as Ansible, OpenStack, Chef, Puppet, Cisco ACI and Vmware vRealize etc.
Conclusion
Before you embark on the automation journey, identify the drivers, tie it to business needs and spend some time to plan the transition by identifying the use cases and tools in use. Script the processes manually and test before automating using tools of your choice.
For more details:
Modern Application Delivery Lifecycle Automation: https://www.radware.com/operator-toolbox/
Application Delivery Management Plug-In: https://www.radware.com/products/vdirect/
Webinar: Automation: The Road to Operational Efficiency: https://event.on24.com/wcc/r/1569004/37B04A217B979A167021F2FC0523FC2F

Read "Keep It Simple; Make It Scalable: 6 Characteristics of the Futureproof Load Balancer" to learn more.
Download Now