When Apple unveiled the iPhone X, it catapulted artificial intelligence and machine learning into the limelight. Facial recognition became a mainstream reality for those who can afford it. A few months later, Vietnamese cyber security firm Bkav claimed it was able to bypass the iPhone X's Face ID using a relatively inexpensive $150 mask. The claim is still up in the air and while it has not been accepted to its full extent, no one was actually able to refute the claim based on scientific facts.
For anyone dealing in AI and security, it emphasized what many of us have held true for a while. We have to use AI, albeit with caution and in its right place. It is a useful tool to have in the armoury to optimize and validate our security posture, but for the actual defence and mitigation a positive security model or behavioural algorithms that are deterministic and predictable are still more effective until the point we will be able to truly trust every possible outcome or decision of Machine and Deep Learning algorithms.

Most applications in use today (successful ones, that is), are based on supervised learning neural nets. The idea behind supervised learning is very simple. They take an input and produce an output where the output is part of a fixed set of labels. For example, it is a common use for email spam filters. It works because the sheer volume of emails provides enough data to ‘learn’ and ‘understand’ which messages are spam, and with time and enough data, a neural net will be able to ‘generalize’ its understanding in such a way that it can classify new messages it has never seen before. Given lots of historical data, the neural net will most of the time make the right ‘decision.’ These sorts of supervised nets can be considered an advanced form of automation. Instead of coding rules into the automation, the automation is coded through data samples and learns by example. They are highly efficient and we shouldn’t underestimate them - they provide a solution for many domains where coding rules would be virtually impossible because of the complexity and our limitations to understand and maintain such complex code as humans. As such, supervised learning opened the door for new applications that were deemed too complex for traditional algorithmic coding.
[You might also like: Cyber Security Predictions]
200 Million Images for a State-of-the-Art Face Recognition System
The fact that the systems learn by example means that they can adapt over time and keep learning, although not without limits. The learning or memory capability, and related to this its performance, depends on the number of nodes in the neural net. The larger the net, the better its performance. Performance however is only as good as the amount of data you put in – large nets need to be fed a lot and to test the performance of a neural network, you need even more data.
[caption id="attachment_7670" align="aligncenter" width="698"]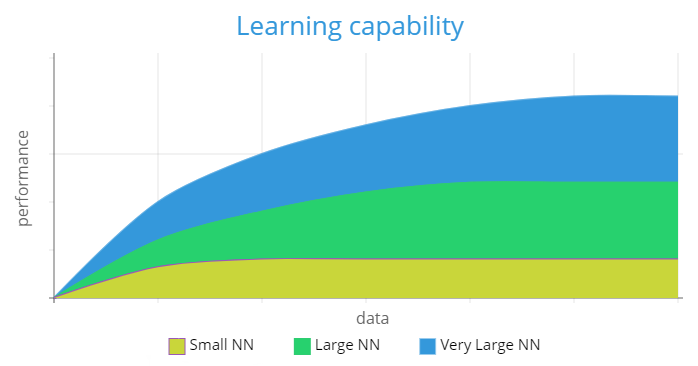 Performance vs size of neural network[/caption]
Performance vs size of neural network[/caption]
To put this in perspective, Andrew Ng, one of the world’s most eminent data scientists, gave some examples of corpus sizes during one of his presentations:
- for speech recognition systems, you need about 10,000h of audio to train the neural net - this is the equivalent of nearly 10 years of sound
- for face recognition, a state of the art system uses over 200 million images.
The WE Economy
Quality and volume of data and consumers are playing an important role in this new world of data science. We like to believe that services embedded in new technologies and (mobile) apps we are consuming are provided to us for ‘free.’ In reality we are paying with our data to feed and improve neural nets. From pictures we store in a cloud drive to navigation systems we feed with our position and speed, we all contribute to improve the quality of the application while enjoying the ‘free’ service. The more people that use the service, the more data, and the better the service becomes. This new so-called ‘we economy’ allows us all to profit from improvement.
But what’s all this got to do with security, and in particular that a positive security model is more effective than any AI system when protecting our applications and infrastructure?
Adversarial Perturbations
There is a problem with neural nets. Nobody understands how the neural net comes to a particular decision and how it generalizes. Generalizing is an important aspect of the neural net because it allows slight deviations of common data patterns to be classified through it. Machine learning is known to be vulnerable to adversarial attacks, where maliciously constructed data is used to force misclassification. Such attacks have been rigorously studied in the context of computer vision.
Researchers have demonstrated on many occasions that artificial neural networks for image recognition can easily be tricked by small perturbations designed specifically to confuse them on a given image. Researchers also found that a single, universal perturbation could cause a network to fail on almost all images, mistaking a coffee-maker for a cobra or a joystick for a Chihuahua. And that these perturbations, also referred to as adversarial perturbations, can be so tiny that they are almost invisible to the naked eye. That’s alarming and shows that these systems are not as robust as one might think.
While attackers are allowed mistakes while using AI to generate new attacks, the defence system that is supposed to block those attacks has zero margin for error - even the slightest error and you might be looking at what could be considered the next Equifax breach.
A more general problem with using raw data to identify ‘baseline’ behaviour for anomaly detection, is that one needs to be certain that the input is completely free of any malicious samples. Also known as poisoning, the overall behaviour of the neural network can be biased before you even start using it. It’s a classic input/output problem – in essence the system isn’t broken, it’s just the data it’s dealing with won’t give the desired outcome.
Unsupervised learning neural nets provide another approach to the anomaly detection problem. As opposed to supervised learning, they do not label outputs and do not require training sets. Unsupervised learning is good at discovering the hidden structure in unlabelled data and hence great for finding anomalies in large pools of unstructured data. However, because there is no labelled input used to train the learner, there is no evaluation of the accuracy of the structure that is output. This means that a large enough amount of malicious data in the pool will go undetected as it would never be considered an anomaly, rather it will be considered as a class of its own.
[You might also like: Chatting With IoT Bots]
Statistical Behavioural Detection
Statistical behavioural detection models have been in use for a long time in the detection of anomalies in traffic patterns and behaviour. Statistical behaviour detection systems are modelled very closely to their problem. It makes them very specific and by consequence cannot be applied to a large set of problems. However, because they model the actual problem they do not need to be trained using very large sets of data and while they can be complex, they are deterministic and humans are able to interpret and understand the decisions made by the system. They are predictable and the parameters for the model can be tuned manually while fine-tuning can be done automatically without too much fear of generating false positives.
The major difference between both solutions is that neural nets are a more general approach and the output cannot be blindly trusted to be used in a system for mitigation or enforcement.
On the other hand, statistical behavioural detection models cannot be applied generally. They are designed to solve or detect a very specific problem. Take for example SYN attacks and the behavioural detection of TCP protocol flags. Statistical detection is modelled very closely on the expected behaviour of the protocol which is described in RFC793. We know what to expect in terms of the ratio of the number of SYNs versus the number of ACKs during the lifetime of a legitimate TCP session between two peers. An exception is therefore easily detectable as an anomaly or attack and false positives are rare because of the algorithm’s intimate modelling based on the knowledge of the protocol.
A neural net can deduce the same, but because it is so general, it will require much more data to train the network before it can start to detect, and it will be much more difficult to predict the certainty of any reported exception without further investigation. Also, because it is so general, it is far easier to poison a neural net where a statistical behaviour algorithm can by design not be poisoned.
Positive Security Models – the Human Intelligence
Closing the loop on positive security models. A positive security model consists of rules that specifically allow certain types of traffic or behaviour. It does not generalize in terms of the input and does not evolve over time, unless adapted by the authority that maintains it. Rules are encoded by humans and they are prone to human error, something which AI and statistical behaviour is less prone to. However, positive security models are very predictable and deterministic and will under no circumstance allow unwanted traffic. That is, if the encoding was strict enough to detect unwanted traffic and prevent false positives, which again comes down to human error.
Bringing Home the Case for AI in Cyber Security
Positive security models are the best way to protect yourself from cyber-attacks where there is a zero-margin for error. But it requires a lot of human intelligence to cover all bases and avoid false positives.
Statistical behaviour modelling is best used in automated mitigation based on anomaly detection when the behaviour is known (such as described in RFCs). It allows immediate enforcement with very little human effort and with less probability to false positives compared to AI, and no risk of poisoning. But it is not universally applicable and multiple different behavioural algorithms might be required to cover more complex behaviour and risks.
The case for AI comes in the area of the very complex, where modelling is virtually impossible. One example is predicting behavioural patterns of users on a network such as in UEBA (User and Entity Behaviour Analytics).
AI also helps us humans to see more clearly in the ever-growing amount of events and data we are collecting from our infrastructure and end-points, and creating associations where we never thought there would be. AI is helping security teams detect anomalies and potentially malicious traffic or events without too much human effort or intelligence. After interpretation and validation, the information retrieved through Big Data and Deep or Machine Learning systems will help security operations improve the positive security model and increase the overall defence capability.
Machine or Deep Learning and AI in general is to be considered an integral part of our security strategy going forward. It allows us to cover more bases and detect gaps in our current security posture whether it is on your premises, in the cloud, by yourself or by security solution providers.
AI is a great tool in many aspects and it is very widely applicable. AI is already impacting the economy in many ways so it’s easy to understand why Andrew Ng calls it ‘the new electricity.’

Download "When the Bots Come Marching In, a Closer Look at Evolving Threats from Botnets, Web Scraping & IoT Zombies" to="" learn="" more.<="" h3="">
Download Now